Top Picks for Software Engineering


Recent posts

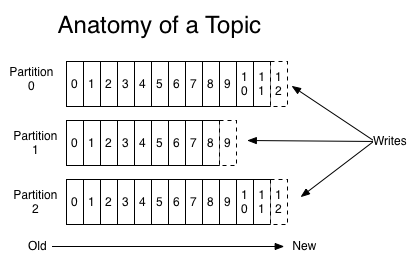
My Mental Model on Choosing a Database for a Particular Problem
Over the years, I have developed a mental model on how I go about to judge whether a certain database technology is the correct one for the problem at hand. This worked well for me when I am designing systems as well as peer reviewing other technical designs. I wanted to share this here in case it helps others, while also serving my selfish need to document this somewhere.

Whiteboard-style Coding Interviews Might Not Be as Bad as You Think
Whiteboard-style coding interviews has a bad reputation, and within the software industry they are being perceived as "bad interview practice" in general. Despite this perception, many companies still hire software engineers through this interviewing process. Are they really that bad? Why do they exist in the way they are today? I cannot promise to give you all the answers, but will at least give you my personal view on this based on my own experience both as an interviewer and interviewee.

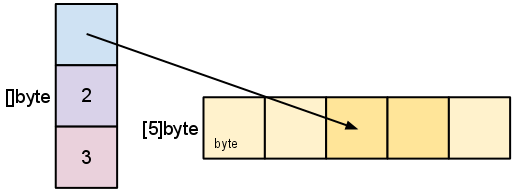
C++, Getting Started with the Basics: Working with Dependencies and Linker
I am learning C++, and what better way to make the learning stick more stronger than blogging about my journey and experience, especially thinking that the barrier to entry is quite high and there is too much to learn. So, the reason that this post exists is a bit selfish, but I am hoping it will be helpful to some other folks who are going through the same struggles as I am. In this post, I will go over details of what it takes to work with dependencies in C++ and how the compilation and linking process works.
Recent speaking activities



Essentials for Building and Leading Highly Effective Development Teams
Let the Uncertainty be Your Friend: Finding Your Path in a Wiggly Road

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
