Kafka Core Concepts and Producer Semantics
Understanding the intrinsic behaviors of a component your system is making use of will make you fear less about it as you will have a better understanding on what might happen under which circumstances. In this post, we will start to understand the core concepts of Kafka as well as diving deep into publishing semantics.
26 May 2020
6 minutes read
Related Posts





Being able to pass data around within a distributed system is the one of the the most crucial aspects of the success for your business, especially when you are dealing with large number of users, reads and writes. It's usual that for a given data write for an entity, you will have N number of read patterns, not just one. Apache Kafka is one of the most effective ways to enable that data distribution within a complex system. I have had the chance to use Kafka at work for more than a year now. However, it has always been implicit and I never needed to understand its intrinsic semantics (standing on the shoulders of giants). I have spent this extended weekend reading the Kafka documentation and running some local examples with Kafka to understand it in details, not just at a high level.
Kafka already has a great documentation, which is very detailed and clear. The intention with this post is not to replicate that document. Instead, it's to pull out bits and pieces which helped me understand Kafka better, and increased by trust. As it has been said in Batman Begins movie (which is one of my all-time favourites): "You always fear what you don't understand", and the main outcome here is to remove that fear :) The post is written by a someone, which is me, who has previous experience with messaging systems such as RabbitMQ, Amazon SQS, and Azure Service Bus. So, I might be overlooking some important aspects which you may also need if you don't have this background. If that's the case, it might be useful to first understand some use cases where Kafka might fit in.
Concepts
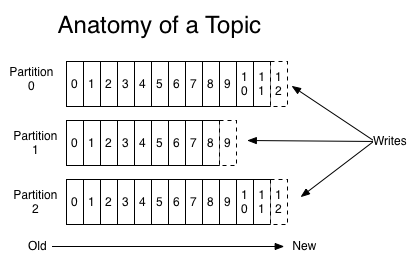
Let's first understand some of the high level concepts of Kafka, which will allow us to get started and work on a sample later on. This is by all means not an exhaustive list of concepts in Kafka but will be enough to get us going by allowing us to extract some facts as well as allowing us to make some assumptions with high confidence.
The most important concept of Kafka is a Topic. Topics in Kafka is a place where you can logically group your messages into. When I say logically, I don't mean a schema or anything. You can think of it as just a bucket where your data will end up in the order they appear, and can also be retrieved in the same order (i.e. continually appended to a structured commit log). Topics can be subscribed to by one or more consumers, which we will touch on that a few points later, but this means that Kafka doesn't have exact message queue semantics, which ensures that the data is gone as soon as one consumer processes the data.
These message are called Records, which are durably persisted in the Kafka cluster regardless of the fact that they have been consumed or not. This differentiates Kafka from queuing systems such as RabbitMQ or SQS, where messages vanish after they are being consumed and processed. Using Kafka for storing records permanently is a perfectly valid choice. However, if this is not desired, Kafka also give you a retention configuration options to specific how long you want to hold onto records per topic basis.
The records gets into (i.e. written) a topic through a producer, who are also responsible for choosing which record to assign to which partition within the topic. In other words, data sharding is handled by the clients which publish data to a particular topic. Depending on what client you use, you may have different options on how to distribute data across the partitions, e.g. round robin, your custom sharding strategy, etc.
The records within a specific topic are consumed (i.e. read) by a consumer, which is part of a consumer group. Consumer groups allow records to be processed in parallel by the consumer instances (which are associated to that group, and can live in separate processes or machines) with a guarantee that a record is only delivered to one consumer instance. A consumer instance within a consumer group will own one or more partitions exclusively, which means that you can have at max N number of consumer if you have N partitions.
So, based on these, here are some take aways which I was able to further unpack by following up:
- Data stored in Kafka is immutable, meaning that it cannot be updated. In other words, Kafka is working with an append-only data structure and all you can do with it is to ask for the next record and reset to current pointer.
- Kafka has a distributed nature to cater your scalability and high availability needs.
- Kafka guarantees ordering for the records but this is only per partition basis and how you retry messages can also have an impact on this order. Therefore, it's safest to assume at the consumption level that Kafka won't give you a message ordering guarantees, and you may need to understanding the details of this further depending on how your messages are distributed across the partitions, and how you plan to process that data.
- Kafka is consumer driven, which means that consumer is in charge of determining reading the data from which position they like. In practical terms, this means that the consumer can reset the offset and start from wherever it wants to. Check out the Offset Tracking and Consumer Group Management sections for more info on this.
- It's possible to add new nodes to your cluster. The data distribution to this node though needs to be triggered manually.
- Related to above, you
can increase the number of partitions for a given topic. However, this is an operation you
do not want to perform without proactively thinking through the consequences since the way you
publish data to Kafka might be impacted by this, if, for example, your sharding strategy is rely on
knowing the partition count (i.e.
hash(key) % number_of_partitions). It's also important to know that Kafka will not attempt to automatically redistribute data in any way. So, this onus is also on you, too.
- There is currently no support for reducing the number of partitions for a topic.
Semantics of Data Producing
On the data producing side, we need to know the topic name and the approach we need to use to distribute data across partitions (which is likely that your client will help on this with some out-of-the-box strategies, such as round-robin as guaranteed by Confluent clients). Apart from this, we have quite a few producer level configuration we can apply to influence the semantics of data publishing.
When I am working with messaging systems, the first thing I want to understand is how the message delivery and durability guarantees are influenced, and what the default behaviour is for these. In Kafka, I found that this story a bit more confusing that it should probably be, which is due to a few configuration settings to be aligned to make it work in favour of durability to prevent message loss. Here are some important configuration for this:
acks: This setting indicates the number of acknowledgments the producer requires for a message publishing to be deemed as successful. It can be set to0, meaning that the producer won't require an ack from any of the servers and this won't give us any guarantees that the message is received by the server. This option could be preferable for cases where we need high throughput at the producing side and the data loss is not critical (e.g. sensor data, where losing a few seconds of data from a source won't spoil our world). For cases where record durability is important, this can be set toall. This means the leader will wait for the full set of in-sync replicas to acknowledge the record, where the minimum number of required in-sync replicas is configured separately.
min.insync.replicas: Quoting from the doc directly: "When a producer setsacksto "all" (or "-1"), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful". This setting is topic level but can also be specified at the broker level. Setting this to the correct amount is really important and it's set to1by default, which is probably not what you want if you care about durability of your messages and you have replication factor of>3for the topic.
flush.messages: In Kafka, messages are immediately written to the filesystem but by default we only fsync() to sync the OS cache lazily. This means that even if we have set our acks and min.insync.replicas to optimise for durability, there is still a theoretical chance that we can lose data with this behaviour. I explicitly said "theoretical" here as it's quite unlikely to lose data with appropriate settings to rely on replication for data durability. For instance, withacks=allandmin.insync.replicas=2settings for a topic which has replication factor of 3, we would be losing data after seeing a data write as successfull in cases of 3 machines (1 leader and 2 replicas) to fail at the same time before having a chance to flush that particular record to the disk, which is pretty unlikely, and this is why Kafka doesn't recommend setting this value as well asflush.msvalue. So, we need to think a bit harder before setting these configuration values as this has some trade-offs to be thought about:- Durability: Unflushed data may be lost if you are not using replication.
- Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
- Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks.
So, a lot to think about here just to get message durability right. The good side of this complexity here is that Kafka is not trying to provide one way to solve all problems, which is not really possible especially when you want to optimise against different aspects (e.g. durability, throughput, etc.) depending the problem at hand. There is some further information on message delivery guarantees in Kafka documentation.
There are some other producer semantics that requires understanding since the consequences of not understanding these might be costly depending on your needs. For example, producer retries is really important to understand correctly as this will have impact on message ordering even within a single partition. Another one is the batch size configuration, which influences how many records to batch into one request whenever multiple records are being sent to the same partition. This might mean that the sends will be performed asynchronously and it may not be suitable for your needs. Finally, the log compaction is another concept which can be really useful to have a prior knowledge on, especially for cases where you publish the current state of an entity to a topic instead of publishing fine-grained events.
Resources

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
