My Mental Model on Choosing a Database for a Particular Problem
Over the years, I have developed a mental model on how I go about to judge whether a certain database technology is the correct one for the problem at hand. This worked well for me when I am designing systems as well as peer reviewing other technical designs. I wanted to share this here in case it helps others, while also serving my selfish need to document this somewhere.
8 April 2021
20 minutes read
Related Posts





Choosing a database technology for the problem at hand is a multifaceted problem. There is usually no single correct choice, but there are surely multiple wrong choices. Depending on the problem you are trying to solve within your unique set of constraints, getting this choice wrong could have significant negative implications on your users and business.
Over the years, I have developed a mental model on how I go about to judge whether a certain database technology is the correct one for the problem at hand. This worked well for me when I am designing systems as well as peer reviewing other technical designs. I wanted to share this here in case it helps others, while also serving my selfish need to document this somewhere.
I have put this together quickly. So, some ideas may not be solidified as effective as they could have been. Please drop a comment if you have any questions, or suggestions.
Dimensions to Think About
There are various dimensions that I consider to be able to make an informed decision about whether a certain database technology fits into the problem which I am trying to solve. These set of dimensions likely to be unique according to the environment and constraints you are working within. However, I have observed some common ones which always came up no matter what type of the environment I was trying to make the choice. I will list them here and explain what I mean by those. However, just keep in mind that this is by no means an exhaustive list. So, if you can think of any others based on your own experience, I would like to hear and learn about them 🙂
Access and Write Patterns
Before you make a choice about a database technology, it's immensely valuable think about your access and write patterns, how the data is written and how you want to query that data. This is to be able to increase your chances to make a correct choice, and it is likely the biggest deciding factor that will let you narrow down your choices as database technologies often differentiate themselves around access patterns, and how the writes are processed.
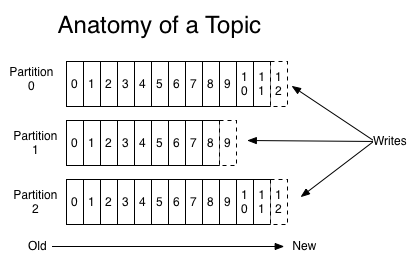
Write pattern is usually the easy part since the writes usually come in a defined shape, and unlikely to change drastically throughout the lifetime of the application. Therefore, writes usually dictate in what shape you want to keep the source of truth. I will talk more about the write pattern within the scalability section below, which is where the real challenge with writes come into the picture. However, there are still a few other considerations you need to keep in mind with writes. For example, what happens if you happen to receive the same write concurrently? You need to have a strategy for dealing with this situation through techniques like optimistic concurrency control, and it's critical to know how your data storage technology can help here. The other important but often overlooked aspect is the idempotent writes. If you want to ensure that the writes are processed exactly once, you might want to employ techniques to mitigate these. For example, DynamoDB's ClientRequestToken parameter acts as an idempotency token and a great example for an out of the box support for this type of problems.
As for the access pattern, it is all about how you want to be querying the data. The reason why this matters, and differs from the write pattern is that it's almost always the case that we need to query the data with a different need in mind compared to how it's written, and more importantly the need for your read pattern often changes (while usually needing multiple patterns per data source). The fact that data access patterns evolve in a much greater velocity than the writes is a too complicated topic to get into here. I will leave CQRS here as a topic for your to explore.
Take the example of a coffee shop which receives orders from each customer, and the loyalty program which needs to give customers points based on their orders and value of those orders. Here, writes are simple: an "order entity" is written into a data storage system and grouped within the orders "bucket" per each customer order. However, the read here is more complex. We need to be able to calculate a loyalty point score per each customer based on their previous orders, and we also need a way to perform this efficiently (i.e. we don't want to scan the entire "bucket" for this).
This was a sort of an easy example, and I am sure you can emphasize here that a lot of data storage systems already have a solution for this problem. So, it may not make much of a difference if your needs are this simple. However, as your access pattern needs get more complex, more differentiation this aspect is going to be putting its weight on your decision making. Take the example of a data access need where you need to find out conflicting events within a given location. The write pattern here is likely to be simple, but the access pattern is a unique one. Not many data storage systems can index for this type of query. So, you need a specific data storage tech to be able to pull this off, or you need to get creative with how you store the data with the potential cost of lower throughput and higher latency on writes.
Another example here is when you need to perform a full-text search over a piece of text across all the rows. Depending on how you want to perform your search (e.g. contains, starts-with, exact word match, etc.), how you want to normalize the search experience (e.g. case-sensitivity, ignoring some stop words such as "and", "or", etc.) and which languages you want to support, this can get pretty complex quite easily. Therefore, the need here needs to be understood before you can make a choice about the data storage technology.
Consistency
The consistency of the data is another pretty important aspect to worry about. For the cases where you attempt to write the data into the database and get a successful ACK back, the databases out there have set different expectations when you happen to read the data again immediately. For example, your data might be written and stored in a durable way. However, you may not see the data you have written immediately, but you are likely given a promise to see the data eventually. This characteristics is commonly refereed as eventual consistency and can have a big negative impact on the system we are designing unless we understand the implications beforehand. There are several reasons why a data storage technology is providing eventual consistency. However, fundamental trade-off here is that you gain either higher availability and/or throughput at the cost of consistency.
In case where you are working against a single node data storage system, the reason you might be facing eventual consistency could be related to the fact that the indexes might be updated asynchronously, meaning at the time when you received an ACK from the database about your write, the index which your query is hitting may not be updated. This is employed to increase throughput as waiting on an index update will take time, and decrease the number of writes you can handle per second.
However, in the case where you are working against a multi-node database structure, where you have replicas, the reason why you might be facing with eventual consistency is likely to be related to the fact that the data hasn't be replicated to the replica node which is being used for the query. In this case, you are actually gaining three benefits:
- further availability (by having the replica which you can failover to),
- higher read throughput (by having the replica which you can use to read data from),
- and higher write throughput (by not replicating the data to each replica synchronously).
Each database is designed work differently with this structure, and it's common to have systems where the replication is performed asynchronously by default to increase write throughput at the cost of eventual consistency. Understanding how each database works and identifying your needs are critical here. In many database systems, there is a way to influence the default replication behavior. For instance, Redis provides a WAIT command which can be used to block the current client until all the previous write commands are successfully transferred and acknowledged by at least the specified number of replicas. While this does not make Redis a strongly consistent store, it increase the changes of data availability to a much higher state, and also increases the changes of consistency as well. Note that this comes with a few costs:
- The writes will take more time to be executed due to the nature of synchronous replication.
- You are performing this at the cost of 'P' from the CAP theorem, which means that your system is no longer Partition tolerant.
MongoDB also offers a similar configuration which is called write concern, and can be set per each write.
There is no simple answer here to indicate one is better than the other. It all depends on your needs, and what type of trade-offs you are happy to make.
Fault Tolerance
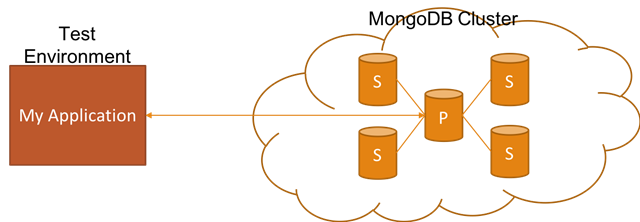
What I mean by fault tolerance here is whether the database can gracefully handle one or multiple nodes going down. When a replica is down, this is usually not a big issue within the setup. A new replica can be spawn up, and can catch up with others through the log of the data storage system (which can be unique to each database technology). However, when the primary node, which handles the writes, is down, it's a bit more serious as there is only one node that handles the writes. In this case, what usually happens is that a new primary is elected from the available replicas through the consensus protocol employed by the database technology. This is what we call failover.
As nearly every data storage system comes with a replication setup and a failover approach, this is less of an issue today, but can still be a deciding factor. The differences usually come down the following points:
- What type of protocol the database system employs to handle consensus, and failover. Raft and Paxos are a few of them. You often don't care about the actual protocol used but you care about the implications such as how hitting common issues like split-brain is handled, how fast the failover detection can happen and whether you have any configuration point to influence this, etc.
- How the clients are handling the failover, e.g. how they perform DNS caching, what is the default timeout to detect a node which is down, etc.
Scalability
One of the most critical parts that can be a differentiator for a database choice. What I mean by scalability here is in terms of both for reads and writes.
Read Scalability
I believe read scalability is largely a commonly solved problem across databases, and easy to reason about by users with some trade-offs such as eventual consistency. So, read scaling will likely not going to be the differentiator. That said, there could be some constraints put by a particular database around read scaling which might be enough to put you off. For example, AWS PostgreSQL Aurora has a hard limit of 15 nodes to be had at max per cluster. That usually doesn't become an issue but I can see how it can be deciding factor.
Write Scalability
On the other hand, things get really interesting when the topic comes to write scaling. Scaling writes have always been much more challenging than scaling the reads, and one of the reasons for this is the shape of the data we have historically stored (i.e. relational data), how we relied on some database features which made this super hard (i.e. database-generated sequential IDs), and how much you as the user of a particular database technology needs to do to scale your writes. However, with the rise of NoSQL databases, the write scaling became much more easier. This waw not because they came with a magical, breakthrough technique or anything. This type of databases just restricted how we were allowed to write the data at the first place, and educated every user about eventual consistency.
If we turn back to our today's World, the common way to solve the problem of write scaling is through sharding, which is the processing of horizontally partitioning the data across multiple different nodes where each of these nodes hold only the subset of the data. The process of how to determine which node holds which data is likely to come down to the user's choice based on the chosen sharding strategy. However, default is likely to perform the data distribution based on the following calculation with simple systems: generating the the hash of the identifier of the data, and taking the modulo of it against the number of shards. Which hashing algorithm to use here is also database technology specific. For example, Redis uses CRC16.
If you identify that you need to perform data partitioning as one node won't be enough to be able to handle the write load, you will be narrowing down your choice significantly as some databases will not get your this functionality out of the box.
However, the real issue starts when it comes to identifying the details of how each database technology makes the sharding work. One interesting aspect here is the resharding part. When you reach to a certain scale with your initial setup (e.g. 5 shards, each having 3 replicas), you might be in need for scaling further. In that scenario, you will be looking into options to add a new shard node to your setup. This will mean that you need to perform an action called resharding, meaning that your data set will be redistributed across nodes, and at least some of the data if not all within the existing shards will move to the newly created shard. This creates a problem with the sharding approach I described above as the clients know that there are only 5 shards, and which node the data needs to be directed to is calculated based on this value. Adding a new shard will start changing things drastically, and will likely introduce downtime to our system unless we are happy to serve the wrong outcome to our users (which we almost never are). More importantly, more data we have across all the nodes, more the downtime we will have which is not a very good scenario to be in.
This is where more clever distribution techniques are employed to allow for zero-downtime resharding to be performed. For example, Redis uses a slot based key distribution model which works really well under resharding scenarios. On the other hand, Cassandra uses a technique called consistent hashing which allows distribution of data across a cluster to minimize reorganization when nodes are added or removed. I don't have much experience with a structure like this but it seems like writes continue to be accepted successfully during the resharding phase.
Elastic Scalability
Also, you should not just be thinking about the today's load demand when it comes to scalability but also project the next 6, 12, 24, 36 months. This will let you see whether your system is likely to meet the demand of the future with your current solution or likely to require a redesign. A good example why this is important could be related to a case when you decide to work with a database from a cloud provider, for instance, PostgreSQL Aurora from AWS. Let's imagine that based on the demand on your read-heavy system today, you can get away with having 5 largest aurora instances where you have one master, and 4 replicas. As Aurora doesn't support data partitioning at the time of this writing, your only choice is to increase the replica size to be able to scale your reads further. This sounds great, as our system is read-heavy (for now, let's assume writes are not an issue, e.g. we have a way to throttle them, etc.), and we can keep adding replicas. However, if we were to project our load against to expected company growth, we may find out that in 12 months, we will be needing 20 replicas instead of 4. That's a problem as Aurora doesn't allow more than 15 nodes per cluster. So, this will likely require a redesign of your system one way or another, and most importantly, you may find out about this limit when you happen to hit the ceiling which could be too late to save the day.
Sometimes though, it’s acceptable to commit to a redesign if we were to need a larger scale, for several reasons, e.g. development velocity. However, this needs to be an explicit call and your team needs to have a shared understanding on this.
Maintenance and Observability
Regular backups, and database engine upgrades are big part of your maintenance. Backups are usually handled pretty well with nearly all databases out there today. However, version upgrades can be a pain and often the issues associated with it are not detected till the first upgrade needs to happen. Finding out the procedure for these tasks before you actually need them are critical, and can be a deciding factor. For instance, if you have no choice but to introduce downtime during version upgrades, it could mean a significant impact to your business. Therefore, that risk might need to be assessed prior to your choice.
Observability is another part which you need to be absolutely on top of from day one. You should be understanding what's happening within your database servers, and have your monitors lined up to detect the potential issues ideally proactively. For example, you need to be able to reason about when you start seeing that your database query latency started to increase for certain queries. Is this happening due to hitting the IOPS limit? Are we saturating other resources of the server such as CPU due to intense indexing caused by elevated writes? Without proper observability, you will be in hell to figure these out. Luckily, many data storage systems are offering near-perfect metrics to gain as good observability as possible.
Related to point above, it's also worth thinking about the operational aspect. For example, when you are on-call, and you are getting paged related to your data storage system, you want to have some actions that you can take with minimum effort and negative implications. This may not be a problem for you today, but it will surely become a problem at some point (remember Murphy's law: Anything that can go wrong will go wrong!).
Self-healing
As mentioned above, anything that can go wrong will go wrong. Paging the on-call engineer to fix an issue related to a database is not the ideal scenario. If you can make your system work within a self-healing mode, you should absolutely invest in doing so. What I mean by self-healing is related to scaling to the elevated need to prevent potential resource saturation issues, healing from failures by performing failovers, resharding when writes start to become a problem, and doing all without needing any intervention.
Some systems offer some of these self-healing operations out of the box. For example, with AWS Aurora, you can configure replication auto-scaling based on several metrics (e.g. average CPU time of all replicas, etc.). With DynamoDB, resharding is performed for you without you knowing nothing about it, which is pretty epic.
Judging the self-healing aspect might bring a pretty big weight for a certain database choice, and could be a differentiating factor. Also, by investing your effort into investigating this area will pay off quite quickly, and you will thank yourself when you go on-call 🙂
Cost
This can be an important distinction especially when you are working with a cloud provider. Depending on your needs, sometimes the cost will make you shy away from a perfect data storage system. For example, consider a write-heavy workload with a predictable, steady amount of writes for the foreseeable future. Considering this requirement, DynamoDB sounds like a near-perfect choice if you are heavily using AWS. However, DynamoDB charges are heavily influenced by write capacity units (and a few other aspects) which is based on the number of writes and how large the data which you are writing into it. The best thing with DynamoDB is the fact that it scales to your needs elasticity but in this case, we already know our load and it's steady. Therefore, a PostgreSQL Aurora instance with a known capacity to handle the predictable load will likely perform much better in terms of cost as the price is set based on the instance size, and amount of data you will be storing.
I would suggest to pay attention to this area, especially if your scale requires it and you have alternative choices. If you happen to narrow down your choice to a single storage system, you might need to still calculate the expected cost but just for FYI purposes rather than being an input to your decision making.
Regulations and Compliance
I am no expert in this area, but I have managed to find my way around it so far. Depending on different regulatory needs which your organization may need to comply with, your database choice may get impacted. This is especially the case when you are going to be storing personally identifiable information (PII). There are several relations to how your data storage system might be concerned with these compliance issues:
- Nearly all regulations I have had to deal with so far required encrypting PII data at rest, meaning that you should store the data on disk as encrypted. Luckily, many databases offer this support out of the box, e.g. MongoDB, DynamoDB.
- Transport level encryption is also something you need to have when connecting to the database from the clients. This is also something which many databases have support for. So, unlikely to be an issue.
- One interesting part with regulations such as GDPR is that it gives users the right to be forgotten, meaning that you should have a way to delete relevant user data from your system upon request from the user within 28 days. For many databases, this is not much of an issue, but some architectural patterns such as event sourcing, and for the database which support this such as EventStoreDB you may need to plan ahead how you can do this, and what would be the implications.
Small Details That Could be Deal Breakers
Besides these, there are some small details which could turn out to be deal breakers depending on your circumstances.
One of them is database client support for a particular programming language. You found the near-perfect database for your needs. However, it turns out that there is no client for the programming language of your choice. Unless you are happy to stop what you are doing and write the client by yourself, this could be a deal breaker. However, there could be some steps you can take to overcome this deficit depending on how many alternative choices you have:
- You might be able to change the programming language especially if you are considering this database to be used within a fresh codebase. This may or may not be applicable to you depending on your appetite and constraints you are working within.
- In case you are thinking about using this database within an existing codebase, you can still take the approach described above but encapsulate the data access logic within a separate service that can be written in a different programming language, and exposed through common transport protocols (e.g. direct use of HTTP/2, or gRPC, etc.).
- In case none of these are options and the database seems to have a C/C++ client, you might be able to wrap this client within the programming language of your choice, if there is a support for this (e.g. Go has this through cgo). This still requires extra initial effort, and potential maintenance effort. So, you should evaluate the trade-offs of going down this road vs. choosing an alternative.
The other one is around licensing. This is usually a concern when you pick an an open source database technology, and that technology turns out not to be open sourced with a permissive license. There could be differences between each license but this might concern you if you are especially distributing the software to your users directly. It's worth double checking the license and getting a clearance before moving forward with a choice.
Practicality of This Mental Model
This mental model worked for me so many times, and most of the choices I have made turned out to be sustainable options. However, you will see that this or similar approaches usually helps the most on narrowing down your choices. Therefore, it's likely that you will end up with multiple options that you can work with, and sometimes the trade-offs will also be balanced, and it might become harder to make a call. When that happens, the best tool in your disposal is going to be benchmarking. This approach will likely get you the most accurate quantitative data you will have in your hand to be able to compare choices, and allow you to gain a more solid perspective.
Also, when we get into the hunt of choosing a database, we may end up forgetting that the best database is sometimes no database. This is especially the case if you are working with ephemeral data which is easily repopulated, and can fit into memory. Not suggesting that this is something you should go with, but it's worth considering it for sure 🙂

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
