I had the privilege to attend NDC Oslo 2016 as a speaker this year. It was a fabulous experience. With this post, I want to share my talk and the list of sessions that grabbed my attention.
Continuous Delivery (4)

NDC Oslo 2016 in a Nutshell
Off to Oslo for NDC Developer Conference
Next week, I am off to Oslo for one of my favorite conferences: NDC Oslo and this time is a little bit more special as I am one of the speakers this year, talking about zero-downtime deployments.
Your Git Repository is Your Deployment Boundary
In this short post, I will try to explain why I think that your Git repository should be your deployment boundary.
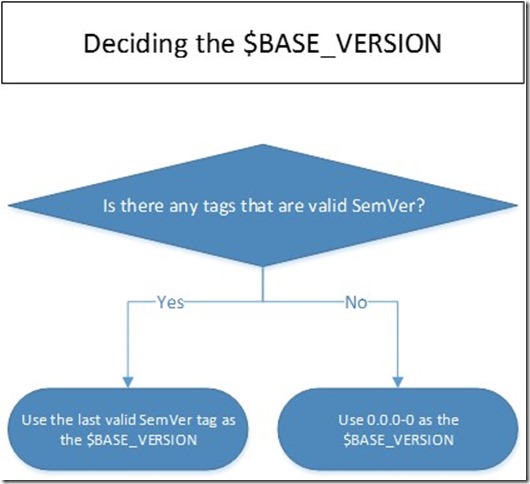
Versioning Software Builds Based on Git Tags and Semantic Versioning (SemVer)
I have been using a technique to set the build version on my CI (continuous integration) system, Travis CI, based on Git tags and semantic versioning (SemVer). In this post, I want to share this with you and give you an implementation of that in Bash.

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
