Last week, I have moved all my personal compute and storage from Azure to AWS, and started managing it through terraform. While doing so, I discovered that you can actually have SSL for your web application without any additional charges when using AWS Application Load Balancer. Setting it up required a few pieces to stich together, and I wanted to share how I configured it through Terraform.
HTTP (11)

Configure Free Wildcard SSL Certificate on AWS Application Load Balancer (ALB) Through Terraform

ASP.NET Core Authentication in a Load Balanced Environment with HAProxy and Redis
Token based authentication is a fairly common way of authenticating a user for an HTTP application. However, handling this in a load balanced environment has always involved extra caring. In this post, I will show you how this is handled in ASP.NET Core by demonstrating it with HAProxy and Redis through the help of Docker.
Long-Running Asynchronous Operations, Displaying Their Events and Progress on Clients
I want to share a few thoughts that I have been keeping to myself on showing progress for long-running asyncronous operations on a system where individual events can be sent during ongoing operations.
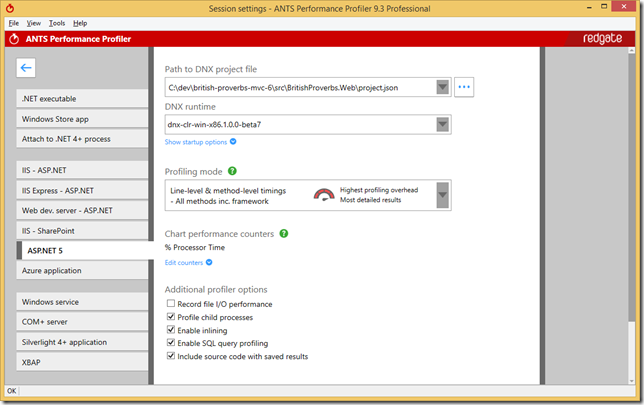
Profiling ASP.NET 5 Applications with ANTS Performance Profiler
ANTS Performance Profiler from Redgate supports ASP.NET 5 applications running on DNX and it allows you to profile your ASP.NET 5 applications to spot performance problems in a really easy and unobtrusive way. In this blog post, I will show you how it can help you with a sample.

Software Applications Should Work Like Restaurants
This is a brain dump blog post which I usually don't do but I needed to get this out of my chest. Restaurants and software applications have some common characteristics in terms of how they need to work and this post highlights some of them.
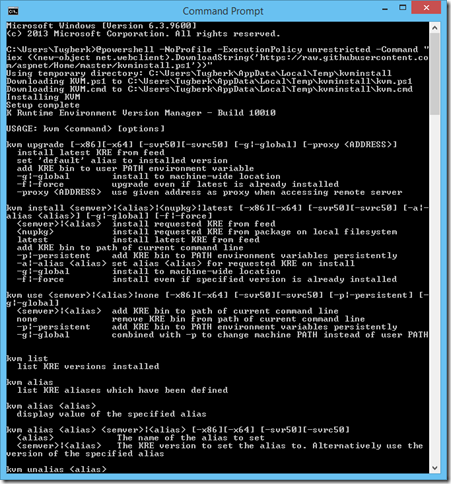
Getting Started with ASP.NET vNext by Setting Up the Environment From Scratch
In this post, I'll walk you through how you can set up your environment from scratch to get going with ASP.NET vNext.
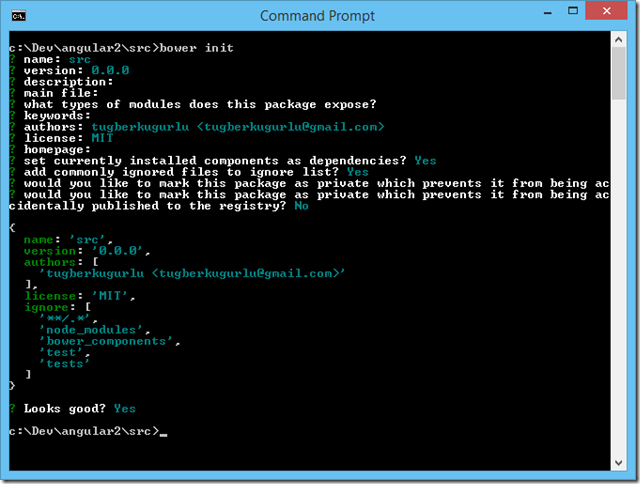
Quickly Hosting Static Files In Your Development Environment with Node http-server
Yesterday, I was looking for something to have a really quick test space on my machine to play with AngularJS and I found http-server: a simple zero-configuration command-line http server.
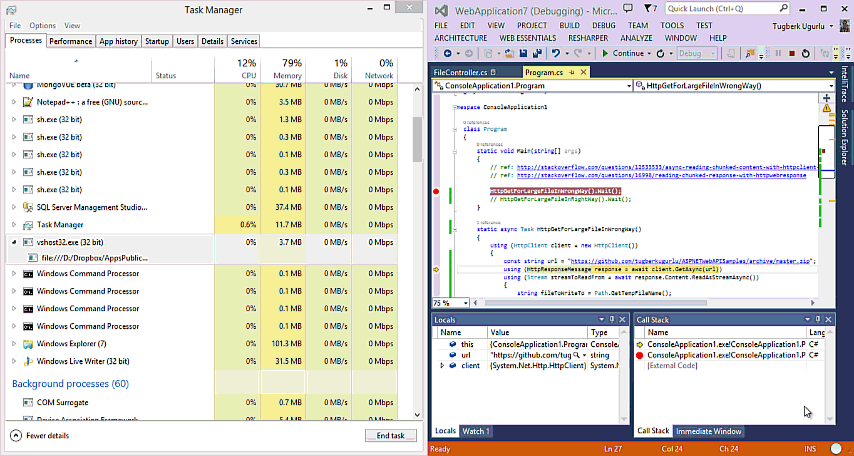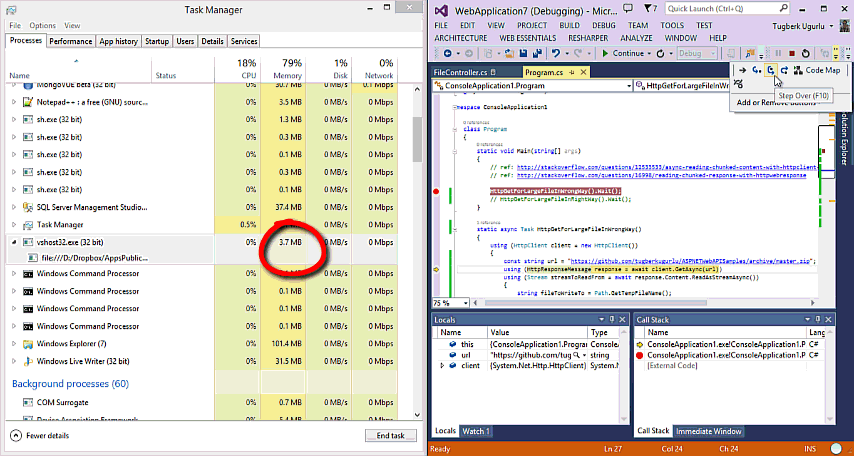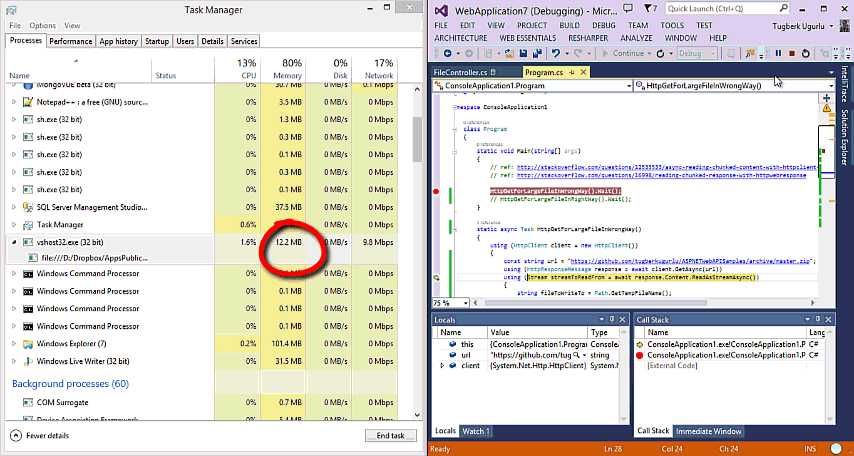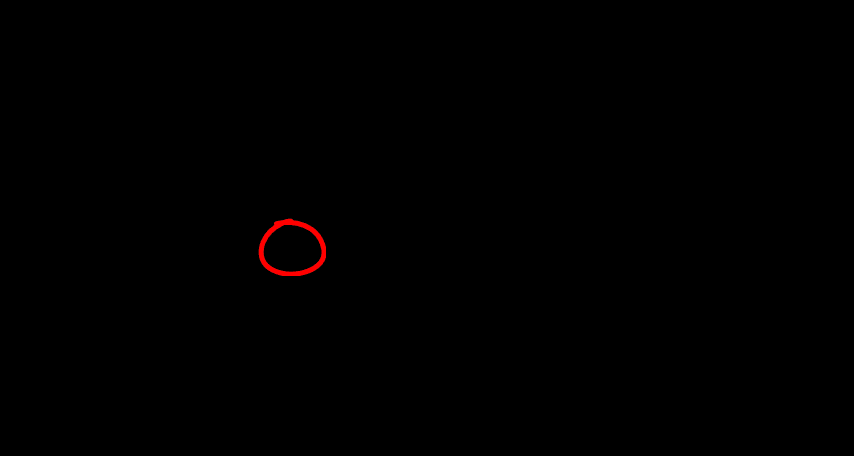
Efficiently Streaming Large HTTP Responses With HttpClient
Downloading large files with HttpClient and you see that it takes lots of memory space? This post is probably for you. Let's see how to efficiently streaming large HTTP responses with HttpClient.
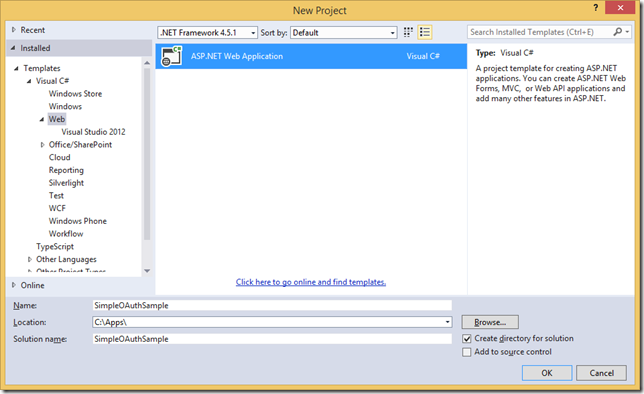
Simple OAuth Server: Implementing a Simple OAuth Server with Katana OAuth Authorization Server Components (Part 1)
In my previous post, I emphasized a few important facts on my journey of building an OAuth authorization server. As great people say: "Talk is cheap. Show me the code." It is exactly what I'm trying to do in this blog post. Also, this post is the first one in the "Simple OAuth Server" series.
My Baby Steps to OAuth 2.0 Hell (or Should I Call It Heaven)
Securing our HTTP API endpoints are one of the biggest challenges we face when writing so-called modern applications and this is where the OAuth 2.0 enters. In this post, I will highlight the things that I have found vital for the last couple of months when I have been working on an OAuth 2.0 Server implementation in .NET Framework.

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
