Easily setting up realistic non-production (e.g. dev, test, QA, etc.) environments is really critical in order to reduce the feedback loop. In this blog post, I want to talk about how you can achieve this if your application relies on MongoDB Replica Set by showing you how to set it up with Docker for non-production environments.
ASP.NET Core (4)
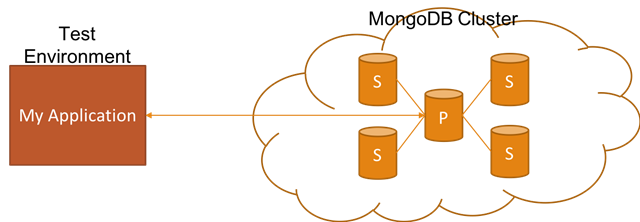
Setting up a MongoDB Replica Set with Docker and Connecting to It With a .NET Core App

ASP.NET Core Authentication in a Load Balanced Environment with HAProxy and Redis
Token based authentication is a fairly common way of authenticating a user for an HTTP application. However, handling this in a load balanced environment has always involved extra caring. In this post, I will show you how this is handled in ASP.NET Core by demonstrating it with HAProxy and Redis through the help of Docker.
Moving to ASP.NET Core RC2: Tooling
.NET Core Runtime RC2 has been released a few days ago along with .NET Core SDK Preview 1. At the same time of .NET Core release, ASP.NET Core RC2 has also been released. While I am migrating my projects to RC2, I wanted to write about how I am getting each stage done. In this post, I will show you the tooling aspect of the changes.

Microsoft Build 2016 in a Nutshell
Two weeks ago, I had an amazing opportunity to be at Microsoft Build Conference in San Francisco and I would like to share my experience about the conference with you in this post by highlighting what has happened and giving you my personal takeaways.

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
