Two weeks ago, I had an amazing opportunity to be at Microsoft Build Conference in San Francisco and I would like to share my experience about the conference with you in this post by highlighting what has happened and giving you my personal takeaways.
Microsoft Azure (5)

Microsoft Build 2016 in a Nutshell
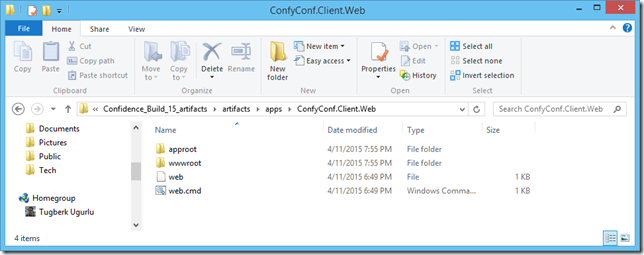
How Azure Web Apps Hosts an ASP.NET 5 Application
ASP.NET 5 application has totally a different directory structure when you try to publish it and it wasn't clear for me how Azure Web Apps is actually able to host an ASP.NET 5 application. If you are confused on this as well, the answer is here.
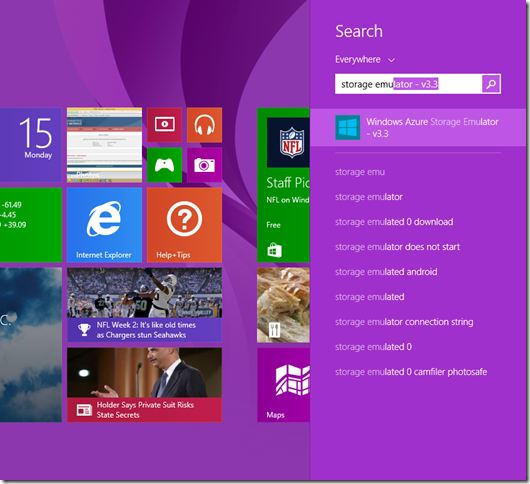
Using Azure Storage Emulator Command-Line Tool: WAStorageEmulator.exe
Starting from version 3.0 of the emulator, a few things have changed and lots of people are not aware of this. When you launch the Storage Emulator now, you will see a command prompt pop up. I wanted to write this short blog post to just to give you a head start.
A Gentle Introduction to Azure Search
Microsoft Azure team released Azure Search as a preview product a few days ago, an hosted search service solution by Microsoft. Azure Search is a suitable product if you are dealing with high volume of data (millions of records) and want to have efficient, complex and clever search on those chunk of data. In this post, I will try to lay out some fundamentals about this service with a very high level introduction.


Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
