Over the years, I have developed a mental model on how I go about to judge whether a certain database technology is the correct one for the problem at hand. This worked well for me when I am designing systems as well as peer reviewing other technical designs. I wanted to share this here in case it helps others, while also serving my selfish need to document this somewhere.
Architecture (9)

My Mental Model on Choosing a Database for a Particular Problem

Redis Cluster - Benefits of Sharding and How It Works
Redis is one of the good friends of a backend engineer, and its versatility and ease of use make it convenient to get started. That said, when it comes to scaling it horizontally for writes, it gets a bit more tricky with different level of trade-offs you need to make. In this post, I want to touch on the basics of Redis Cluster, out of the box solution of Redis to the gnarly write scaling problem.
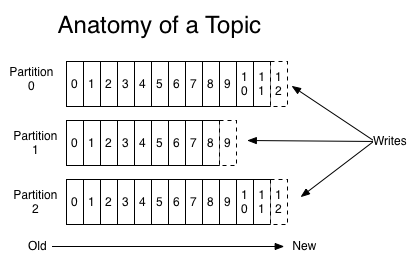
Kafka Core Concepts and Producer Semantics
Understanding the intrinsic behaviors of a component your system is making use of will make you fear less about it as you will have a better understanding on what might happen under which circumstances. In this post, we will start to understand the core concepts of Kafka as well as diving deep into publishing semantics.
Software Architecture and System Design - Getting Your Grip and Some Related Resources
If you have never been exposed to software system design challenges, you might be totally lost on even where to begin. Dive into this post to find out about what matters when it comes to software architecture and system design and how you can get your grip in this wide area of software engineering.

Pulling an Old Article From the Coffin: SignalR with Redis Running on a Windows Azure Virtual Machine
Long time ago (about 5 years, at least), I contributed an article to SignalR wiki about scaling SignalR with Redis. You can still find the article here. I also blogged about it here. However, over time, pictures got lost there. I got a few requests from my readers to refresh those images and I was luckily able to find them :) I decided to publish that article here so that I would have a much better control over the content.
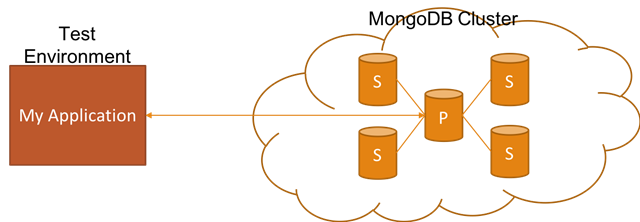
Setting up a MongoDB Replica Set with Docker and Connecting to It With a .NET Core App
Easily setting up realistic non-production (e.g. dev, test, QA, etc.) environments is really critical in order to reduce the feedback loop. In this blog post, I want to talk about how you can achieve this if your application relies on MongoDB Replica Set by showing you how to set it up with Docker for non-production environments.

ASP.NET Core Authentication in a Load Balanced Environment with HAProxy and Redis
Token based authentication is a fairly common way of authenticating a user for an HTTP application. However, handling this in a load balanced environment has always involved extra caring. In this post, I will show you how this is handled in ASP.NET Core by demonstrating it with HAProxy and Redis through the help of Docker.
Long-Running Asynchronous Operations, Displaying Their Events and Progress on Clients
I want to share a few thoughts that I have been keeping to myself on showing progress for long-running asyncronous operations on a system where individual events can be sent during ongoing operations.

Software Applications Should Work Like Restaurants
This is a brain dump blog post which I usually don't do but I needed to get this out of my chest. Restaurants and software applications have some common characteristics in terms of how they need to work and this post highlights some of them.

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
