In this short post, I will try to explain why I think that your Git repository should be your deployment boundary.
Git (7)
Your Git Repository is Your Deployment Boundary
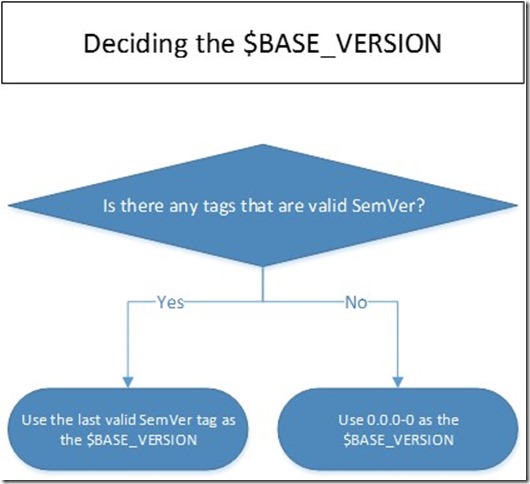
Versioning Software Builds Based on Git Tags and Semantic Versioning (SemVer)
I have been using a technique to set the build version on my CI (continuous integration) system, Travis CI, based on Git tags and semantic versioning (SemVer). In this post, I want to share this with you and give you an implementation of that in Bash.

Resistance Against London Tube Map Commit History (a.k.a. Git Merge Hell)
It's so easy to end up with git commit history which looks like London tube map. Let's see how we end up with those big, ugly, meaningless commit histories and how to prevent having one.
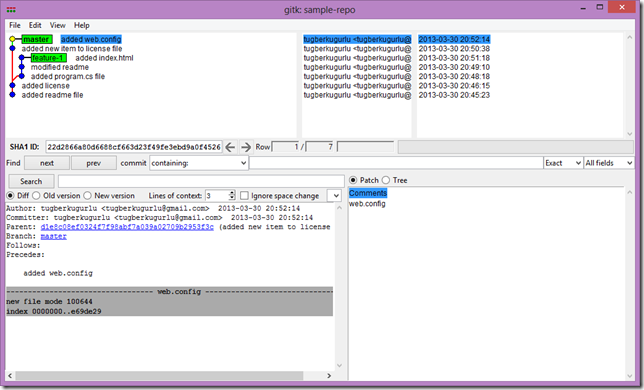
Basics of Git Rebase
Git Rebase is only one of the powerful features of git and it allows you to have a clean history in a highly branching workflow.
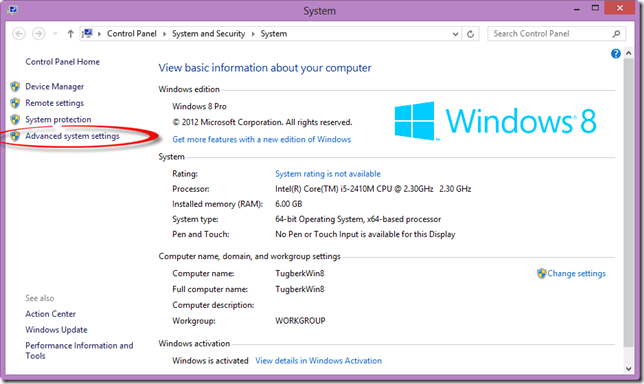
Installing hub Extension for Git (by defunkt) on Windows to Work With GitHub More Efficiently
This post walks you through on how you can install hub extension for Git (by defunkt) on Windows to work with GitHub more efficiently.

Sides and Source Code for DEU Bilgisayar Topluluğu Izmir 2. Teknoloji Zirvesi
This weekend, I participated in an event as a speaker in Izmir, DEU Bilgisayar Topluluğu Izmir 2. Teknoloji Zirvesi. Sides and Source Code for my sessions are available.
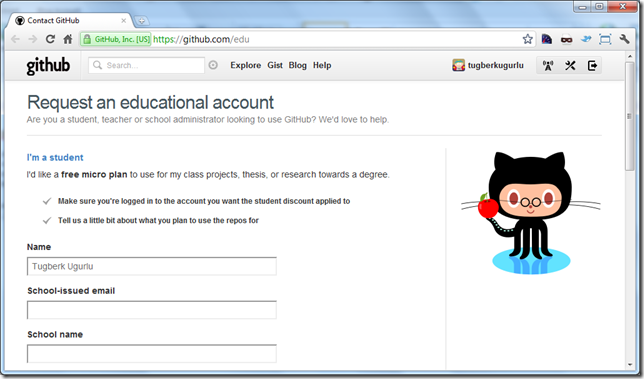
GitHub Offers Free Micro Plan For Students For Two Years
Couple of days ago I came across that GitHub offers Educational Accounts for academic people (student, teacher, etc.) and that covers free micro plan for students for 2 years.

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
