I have been using a technique to set the build version on my CI (continuous integration) system, Travis CI, based on Git tags and semantic versioning (SemVer). In this post, I want to share this with you and give you an implementation of that in Bash.
SemVer (2)
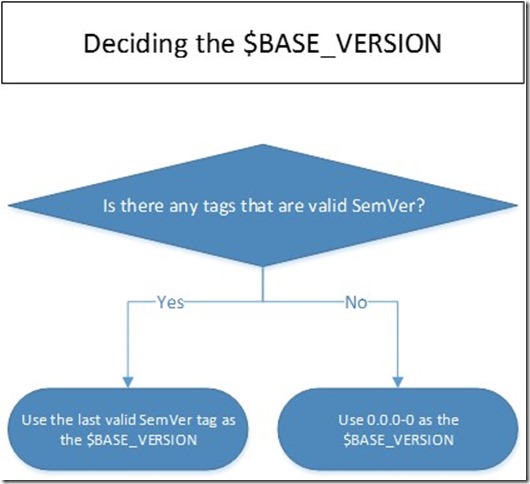
Versioning Software Builds Based on Git Tags and Semantic Versioning (SemVer)
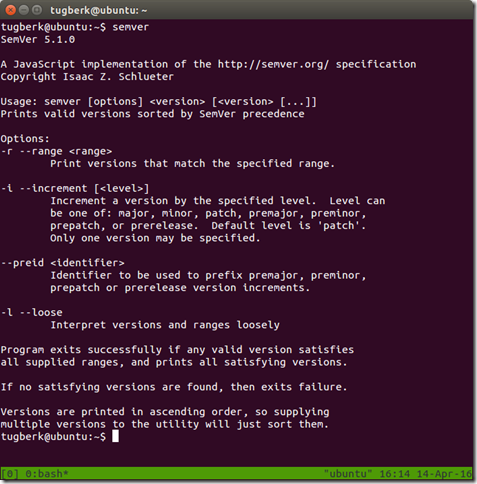
node-semver: CLI Tool for Semantic Versioning 2.0.0
14 April 2016
·
2 minutes read
In this post, I want to tell you about node-semver, a SemVer 2.0.0 parser command-line tool and a node.js library (the one that npm uses).

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡

Tags
ASP.Net
101
.NET
75
ASP.NET Web API
49
ASP.NET MVC
42
C#
36
Geek Talks
30
SignalR
16
ASP.NET 5
16
Tips
14
Visual Studio
11
async
11
HTTP
11
Windows Azure
10
Tourism
10
Architecture
9
TPL
9
ASP.NET vNext
8
OWIN
8
Katana
7
Git
7
JQuery
7
Microsoft
6
MongoDB
6
NuGet
6
DLM
6
Deployment
6
PowerShell
6
MS SQL
6
JavaScript
6
Razor
5
DbContext
5
Algorithms
5
Docker
5
Unit Testing
5
Microsoft Azure
5
Entity Framework
5
Data Structures
5
Redis
5
Career
4
ASP.NET Core
4
UNWTO
4
Software Development
4
Hosting
4
SQL Server
4
Elasticsearch
4
IIS
4
Continuous Delivery
4
IT Stuff
4
.NET Core
4
GitHub
4
Caching
3
Go
3
Security
3
Databases
3
Software Engineer
3
Golang
3
Distributed Systems
3
Deployments
2
Blogging
2
Interviewing
2
gulp
2
Assignments
2
Aspect Oriented Programming
2
SQL Release
2
Random
2
Code Review
2
Linux
2
Continuous Integration
2
WCF Web API
2
Polyglot Persistance
2
RavenDB
2
Autofac
2
Azure Search
2
SemVer
2
Facts & Figures
2
OAuth
2
PostSharp
2
C++
2
nodejs
2
Graph
1
Tech Guys
1
MvcScaffolding
1
Projects
1
Web.Config
1
Concurrency
1
Bash
1
Congress & Convention Tourism
1
UX
1
SQL Injection
1
Sharding
1
Microsoft SQL Server
1
Docker Compose
1
Web Application
1
TourismGeek
1
Dexter
1
Travis CI
1
Windows Live Writer
1
Kafka
1
Go Slices
1
Octopus Deploy
1
Web
1
Search
1
Roslyn
1
Business
1
Redux
1
eCommerce
1
Programming
1
Microsoft Office
1
Continious Delivery
1
Blob Storage
1
Time Saviour
1
Scaling
1
MVP
1
Windows 8
1
AWS
1
Windows Server AppFabric
1
tugberkugurlu.com
1
Azure Web Apps
1
Messaging
1
NGINX
1
Software
1
Tourism Business
1
Neo4j
1
Azure Storage
1
TV Series
1
Lucene.NET
1
Azure
1
xUnit
1
Excel
1
Visual Basic
1
Identity
1
React
1