Today is one of those awesome days if you build stuff on .NET platform. They announced bunch of stuff during Build 2015 keynote and one of them is Visual Studio Code, a free and stripped down version of Visual Studio which works on Mac OS X, Linux and Windows. Let me give you my highlights in this short blog post :)
C# (36)
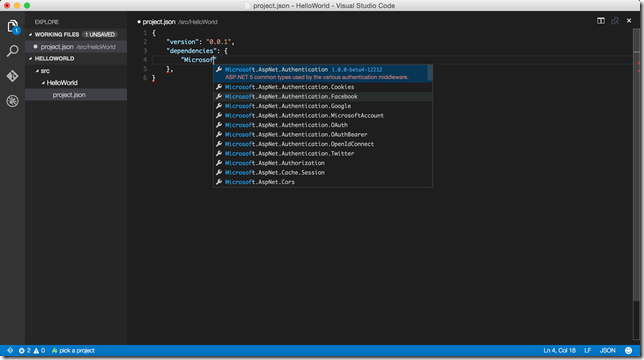
First Hours with Visual Studio Code on Mac and Windows

Compiling C# Code Into Memory and Executing It with Roslyn
Let me show you how to compile a piece of C# code into memory and execute it with Roslyn. It is super easy if you believe it or not :)
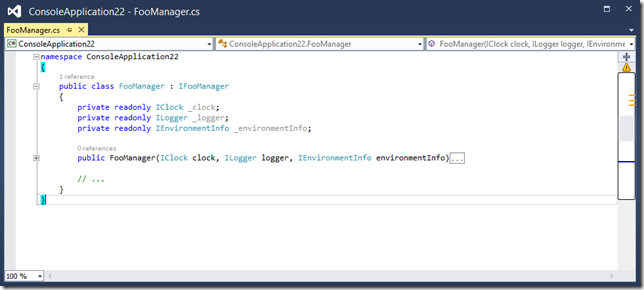
Dependency Injection: Inject Your Dependencies, Period!
Reasons on why I prefer dependency injection over static accessors.
Should I await on Task.FromResult Method Calls?
Task class has a static method called FromResult which returns an already completed (at the RanToCompletion status) Task object. I have seen a few developers "await"ing on Task.FromResult method call and this clearly indicates that there is a misunderstanding here. I'm hoping to clear the air a bit with this post.
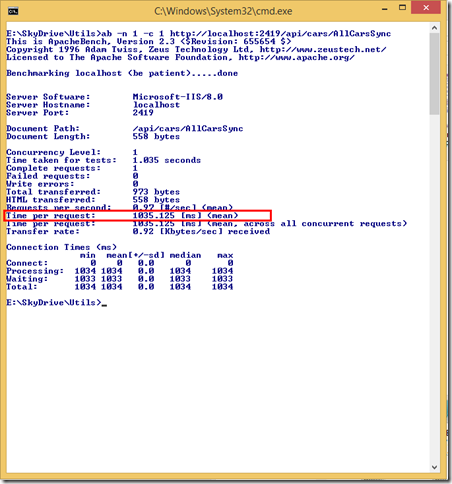
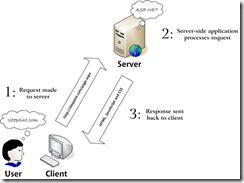
How and Where Concurrent Asynchronous I/O with ASP.NET Web API
When we have uncorrelated multiple I/O operations that need to be kicked off, we have quite a few ways to fire them off and which way you choose makes a great amount of difference on a .NET server side application. In this post, we will see how we can handle the different approaches in ASP.NET Web API.
Hierarchical Resource Structure in ASP.NET Web API
This post explains the concerns behind the hierarchical resource structure in ASP.NET Web API such as routing, authorization and ownership.

List of Resources on Asynchronous Programming for .NET Server Applications with C#
I listed some resources on asynchronous programming for .NET server applications with C# which consist of blog posts, presentations and podcasts.
Streaming with New .NET HttpClient and HttpCompletionOption.ResponseHeadersRead
How to consume a streaming endpoint with new .NET System.Net.Http.HttpClient and the role of HttpCompletionOption.ResponseHeadersRead
Disposing Resources At the End of the Request Lifecycle in ASP.NET Web API
How to disposing resources at the end of the request lifecycle in ASP.NET Web API with the RegisterForDispose extension method for the HttpRequestMessage class

The Perfect Recipe to Shoot Yourself in The Foot - Ending up with a Deadlock Using the C# 5.0 Asynchronous Language Features
Let's see how we can end up with a deadlock using the C# 5.0 asynchronous language features (AKA async/await) in our ASP.NET applications and how to prevent these kinds of scenarios.
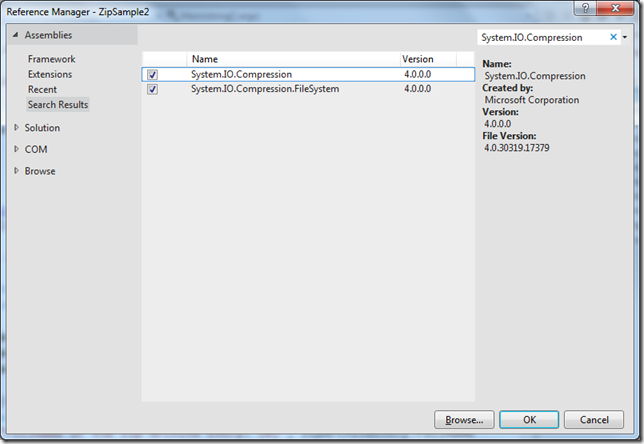
.NET 4.5 to Support Zip File Manipulation Out of the Box
One of the missing feature of .NET framework was a support for Zip file manipulation. In .NET 4.5, we have an extensive support for manipulating zip archives.
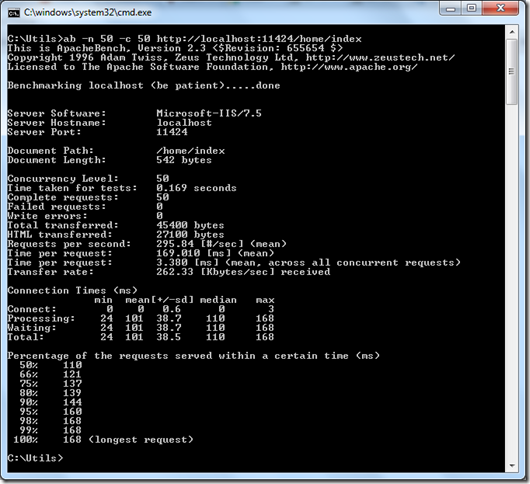
Asynchronous Database Calls With Task-based Asynchronous Programming Model (TAP) in ASP.NET MVC 4
Asynchronous Database Calls With Task-based Asynchronous Programming Model (TAP) in ASP.NET MVC 4 and its performance impacts.

Slides of My MS Web Platform & ASP.NET MVC 101 Talks
Today, I was at Computer Engineering Department of Mugla University and I gave two introduction talks on MS Web Platform and ASP.NET MVC 101.
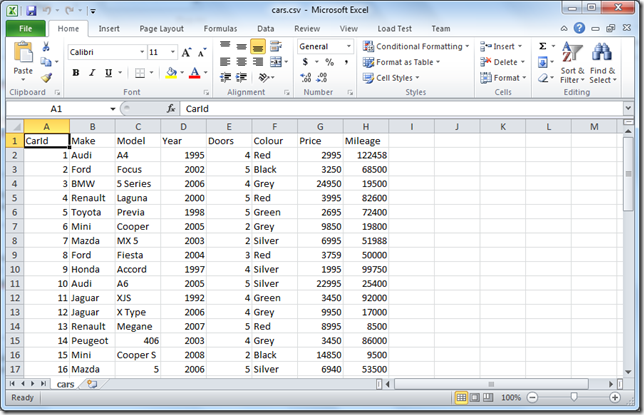
Creating Custom CSVMediaTypeFormatter In ASP.NET Web API for Comma-Separated Values (CSV) Format
In this post, we will see how to create a custom CSVMediaTypeFormatter in ASP.NET Web API for comma-separated values (CSV) format
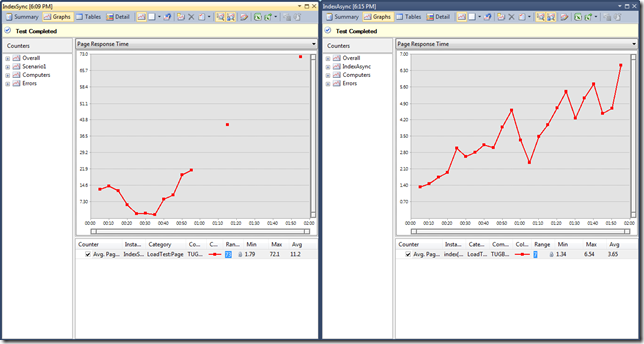
My Take on Task-base Asynchronous Programming in C# 5.0 and ASP.NET MVC Web Applications
I'm trying to show you what new C# 5.0 can bring us in terms of asynchronous programming with await keyword. Especially on ASP.NET MVC 4 Web Applications.
ASP.NET MVC Code Review #2 - A Way of Working with Html Select Element (AKA DropDownList) In ASP.NET MVC
This is the #2 of the series of blog posts which is about some core scenarios on ASP.NET MVC: A Way of Working with Html Select Element (AKA DropDownList) In ASP.NET MVC
ASP.NET MVC Code Review #1 - File Upload With HttpPostedFileBase Class
This is #1 of the series of blog posts which is about some core scenarios on ASP.NET MVC: File Upload With HttpPostedFileBase Class
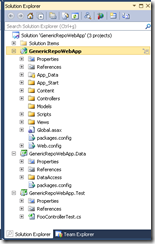
How to Work With Generic Repositories on ASP.NET MVC and Unit Testing Them By Mocking
In this blog post we will see how to work with generic repositories on ASP.NET MVC and unit testing them by mocking with moq
Generic Repository Pattern - Entity Framework, ASP.NET MVC and Unit Testing Triangle
We will see how we can implement Generic Repository Pattern with Entity Framework and how to benefit from that.
Introduction to WCF Web API - New REST Face of .NET
This blog post will give you an introduction to WCF Web API and show you how to get started with WCF Web API along with Dependency Inject support with Ninject.
ASP.NET MVC Server Side Remote Validation
In this quick post, I will show you a way of implementing ASP.NET MVC Server Side Remote Validation just like ASP.NET MVC Remote Validation

Donut Hole Caching In ASP.NET MVC by Using Child Actions and OutputCacheAttribute
This blog post demonstrates how to implement Donut Hole Caching in ASP.NET MVC by Using Child Actions and OutputCacheAttribute

ASP.NET MVC Remote Validation For Multiple Fields With AdditionalFields Property
This post shows the implementation of ASP.NET MVC Remote Validation for multiple fields with AdditionalFields property and we will validate the uniqueness of a product name under a chosen category.
Check Instantly If Username Exists - ASP.NET MVC Remote Validation
This blog post will walk you through on implementation and usage of ASP.NET MVC Remote Validation. As a sample, we will validate the availability of the username for membership registration.
Working With JQuery Ajax API on ASP.NET MVC 3.0 - Power of JSON, JQuery and ASP.NET MVC Partial Views
In this post, we'll see how easy to work with JQuery AJAX API on ASP.NET MVC and how we make use of Partial Views to transfer chunk of html from server to client with a toggle button example.
TinyMCE HTML Text Editior & ASP.NET MVC - Setting It Up Has Become Easy With Nuget
One of the best Javascript WYSIWYG Editors TinyMCE is now up on Nuget live feed. How to get TinyMCE through Nuget and get it working is documented in this blog post.
ASP.NET Web Forms : Calling Web Service Page Methods Using JQuery
In this blog post we will see how to consume a web page methods using JQuery on ASP.NET Web Forms and use ASP.NET page methods as services. You will find some cool stuff about other things as well :)

Parent / Child View In a Single Table With GridView Control On ASP.NET Web Forms
This awesome blog post will demonstrate how to create a complete, sub-grouped product list in a single grid. Get ready for the awesomeness...

How To Handle Multiple Checkboxes From Controller In ASP.NET MVC - Sample App With New Stuff After MVC 3 Tools Update
In this blog post, we will see how to handle multiple checkboxes inside a controller in ASP.NET MVC. We will demonstrate a sample in order to delete multiple records from database.

We Love .NET 4 - Clean Web Control IDs with ClientIDMode Property to Static and Predictable
In this blog post, we will see how ClientIDMode property of Web Controls makes our lives easier. Also, we will demonstrate couple of scenarios on how it works...
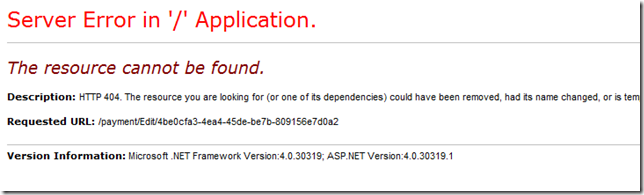
ASP.NET MVC : Throwing 404 Exceptions Manually From Controller When Model is Null
This post is a quick demonstration of how you can throw HttpException of 404 manually from a controller on ASP.NET MVC when the model you're passing is null
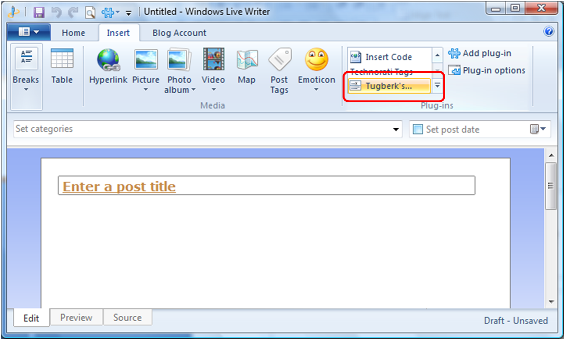
Windows Live Writer Codehighlighting Plugin For Alex Gorbatchev's SyntaxHighlighter
Windows Live Writer Codehighlighting Plugin For Alex Gorbatchev's SyntaxHighlighter is available on codeplex

Sending E-mail to All List of Membership Users with ASP.Net Using Built-in Membership API
Most of the Asp.Net developers are using Membership class of Asp.Net and in this blog post we will see how to send e-mail to all of the membership users at once...
How to Delete a Previously Created Cookie With C# ASP.Net / Deleting Cookie ASP.Net
You created a cookie on you asp.net forms application now you would like to delete it. This quick article show how to do the trick...
How To Use C# (C Sharp) Switch Case, Switch Case Samples
After you read this article, you will be able to use the 'Switch Case' Function on your C# Projects. This function becomes so handy with DropDownList & RadioButtonList !
How to Validate A CheckBox in ASP.Net 3.5 / Checkbox Validation Control Sample Code in ASP.Net, C# (C Sharp) And Visual Basic
This article will give you an idea to validate a checkbox in ASP.Net 3.5 ! It is so easy to implement and so handy to use !

Hey, I'm Tugberk 👋
Coder 👨🏻💻, Speaker 🗣, Author 📚, ex-Microsoft MVP 🕸, Blogger 💻
I live in London, UK 🏡
